目次
- はじめに
- プロジェクトの作成
- 設計
- 実装
- 作成したバッチ処理を実行する
- おわりに
1. はじめに
この記事は初めてバッチ処理のタスクを振られたエンジニアがバッチ処理の概要を理解して, Spring Batchで基本的なバッチ処理を実装できるようになる事を目標にしています。
記事は以下の通りの内容で何回かに分けて投稿します
- 第1回: バッチ処理とSpring Batchの概念を説明する
- 第2回: TaskletモデルでHello Worldを出力するバッチを実装する(当記事)
- 第3回: Spring BatchのTaskletモデルでCSVを読み込んで加工して結果を別のCSVに書き込む処理を実装することを通して, Spring Batchの基本機能の使い方を学ぶ
- 最終回: バッチ処理を実装する際の注意事項について
第一回の記事で紹介した通り, Spring Batchの典型的な流れは、JobLauncherによってJobが開始され、Jobによって複数のStepが実行され、Step内ではデータの読み込み処理・加工処理・書き込み処理がなされるといった感じです(図1)。
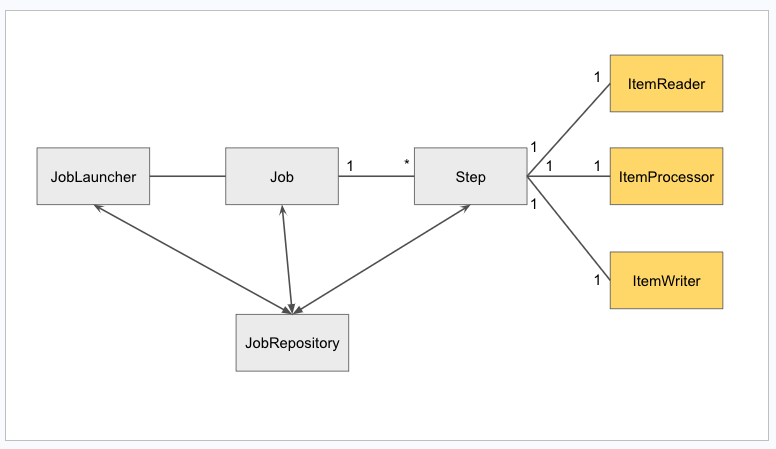
この図1のStepの実装方法には2つのモデルがあり、図1のようにデータ読み込みクラス・加工クラス・書き込みクラスを分けるモデルをChunkモデルと呼びます。一方で、データの書き込み処理は必要ない場合などはTaskletという1つのクラス内にデータを扱う処理を実装することがあります。これをTaskletモデルと言います。
まずはTaskletモデルでHello Worldを出力するバッチ処理を実装してみましょう。
ゴールはバッチ処理を実行したら、写真1のようにコンソールに「Hello World」という文字が出力されるようにすることです。

2. プロジェクトの作成
それではプロジェクトを作っていきましょう。
今回はSpring Initializrを使ってSpringプロジェクトの雛形を作っていきます(写真2)。
このリンクから写真2の設定のSpring Initializrにアクセスできます。
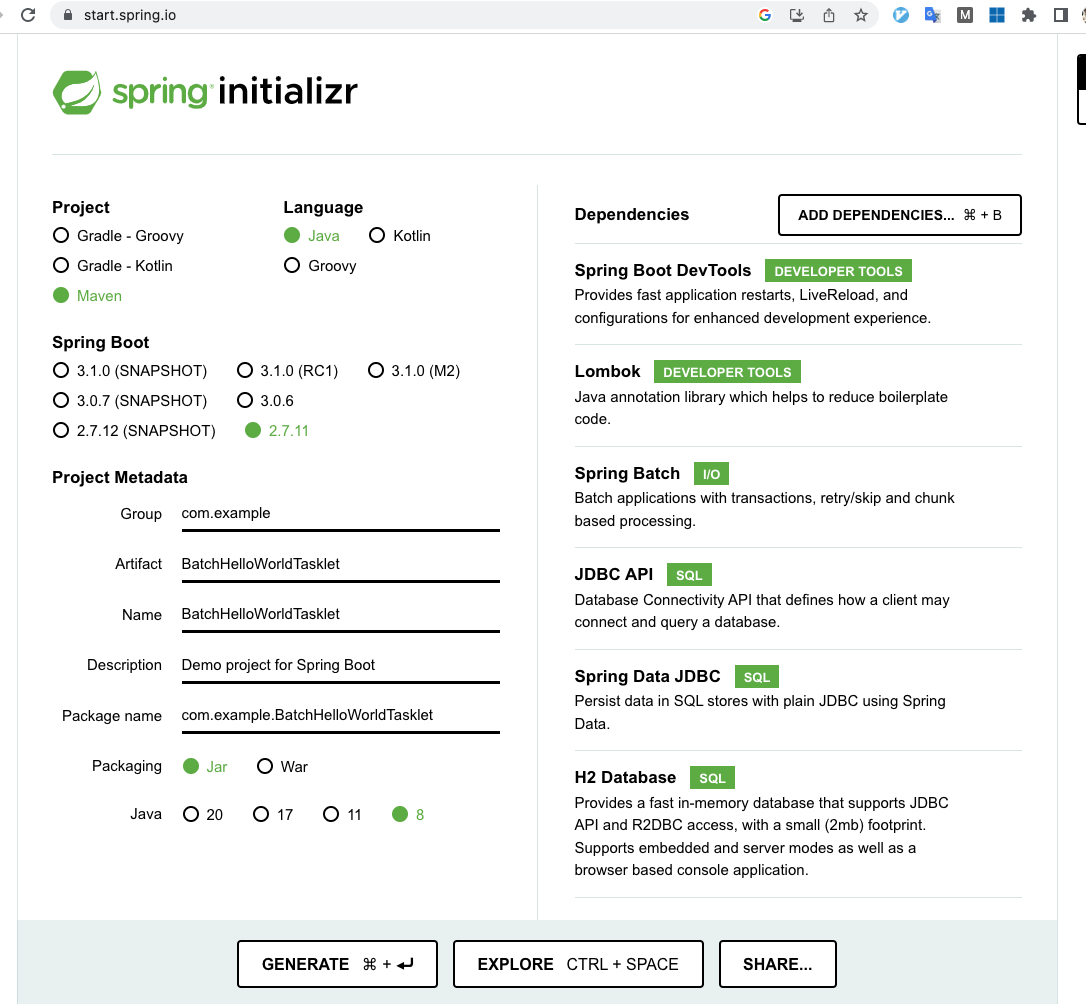
問題がなければ、Generateを押してプロジェクトのzipファイルをダウンロードして、任意のディレクトリで解凍してIntteli J IDEAなどのIDEで開いてください(EclipseでもOK)。
注意点ですが、今回は筆者のプロジェクトで使っているバージョンを利用するために、Spring Batchのバージョンが4.x系、Javaが8を使っています。
中には最新バージョンのSpring Boot・Spring Batchではコンパイルが通らないことがありますので、Spring Batchを5.x系でやりたい場合は適宜読み替えながらやってください。
3. 設計
簡単に設計を見ていきましょう。
今回は主に2つのクラスを実装していきます。
1番のクラスでは、Taskletの具体的な処理を記述していきます。 ここでHello Worldをログに出力する処理を記述します。
2番のクラスでは、バッチ処理の設定を行うために、どのJobがどのStepを呼び出しており、StepがどのTaskletを呼び出しているか?という内容を記述していきます。ここでStepから1番のTaskletを呼び出すことで、このStepを呼び出しているJobクラスを実行することでバッチ処理を実行してログにHello Worldと出力できます。
4. 実装
それでは具体的な実装を行っていきましょう。
4.1. Taskletクラスの実装
まずは1番のTaskletのクラスを実装していきます。
ターミナルを開いてBatchHelloWorldTasketディレクトリに移動して、以下の通りにtaskletというディレクトリとHelloTasklet.javaというファイルを作成しましょう。 mkdirから末尾までで1コマンド、touchから末尾までで1コマンドです。
➜ BatchHelloWorldTasklet $ mkdir src/main/java/com/example/BatchHelloWorldTasklet/tasklet ➜ BatchHelloWorldTasklet $ touch src/main/java/com/example/BatchHelloWorldTasklet/tasklet/HelloTasklet.java
HelloTasklet.javaを開いて以下の通りに記述してください。
package com.example.BatchHelloWorldTasklet.tasklet; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.StepContribution; import org.springframework.batch.core.configuration.annotation.StepScope; import org.springframework.batch.core.scope.context.ChunkContext; import org.springframework.batch.core.step.tasklet.Tasklet; import org.springframework.batch.repeat.RepeatStatus; import org.springframework.stereotype.Component; // (2). Taskletは@ComponentをつけてBeanとしてDIコンテナに登録する必要がある @Component // (3). インスタンスの生存期間をStepの開始から終了までに指定 @StepScope // log出力を行うために使用する @Slf4j // (1). Taskletインタフェースを実装すればTaskletの処理を作れる public class HelloTasklet implements Tasklet { // (4). TaskletインタフェースのexecuteメソッドがStepで実行される。 @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (5). ログを出力する log.info("Hello World"); // (6). Taskletを終了する繰り返しステータスを返す return RepeatStatus.FINISHED; } }
要点を絞って(1)~(5)まで1つずつ解説していきます。
まずTaskletを作る際は、(1)のようにTaskletの処理を行うクラスにTaskletインタフェースを実装するように設定します。
// (1). Taskletインタフェースを実装すればTaskletの処理を作れる public class HelloTasklet implements Tasklet { 略 }
そしてTaskletを使用できるようにするために、(2)のように@Componentアノテーションをクラスに付けて、TaskletをBeanとしてDIコンテナに登録されるように設定します。
// (2). Taskletは@ComponentをつけてBeanとしてDIコンテナに登録する必要がある @Component public class HelloTasklet implements Tasklet { 略 }
次に、Taskletのインスタンスの生存期間をStep内にするために、@StepScopeアノテーションを付けます。
@Component // (3). インスタンスの生存期間をStepの開始から終了までに指定 @StepScope public class HelloTasklet implements Tasklet { }
次に、(4)番でStepによってTaskletが呼び出された際に実行される具体的な処理をexecuteというメソッド使って書いていきます。executeメソッドはTaskletインタフェースで定義されているメソッドであり、それの具体的な処理をここで記述します。
そして、(5)番でHello Worldとログに出力する処理を記述します。 最後に、(6)番でTaskletの繰り返しステータスとしてRepeatStatus.FINISHEDをStepに返すことで、このTaskletを繰り返さないことをStepに伝えます。
public class HelloTasklet implements Tasklet { // (4). TaskletインタフェースのexecuteメソッドがStepで実行される。 @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (5). ログを出力する log.info("Hello World"); // (6). Taskletを終了する繰り返しステータスを返す return RepeatStatus.FINISHED; } }
4.2 BatchConfigクラスの実装
Taskletの実装が終わったので、次はTaskletを呼び出すStep、Stepを呼び出すJobを記述するバッチ処理の設定クラスを作成していきます。
まずは、以下の通りパッケージとクラスを作成します。
➜ BatchHelloWorldTasklet $ mkdir src/main/java/com/example/BatchHelloWorldTasklet/config ➜ BatchHelloWorldTasklet $ touch src/main/java/com/example/BatchHelloWorldTasklet/config/BatchConfig.java
それでは、BatchHelloWorldTasklet.javaを開いてStepとJobを記述してバッチ処理を完成させましょう。
package com.example.BatchHelloWorldTasklet.config; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.core.step.tasklet.Tasklet; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; // (2). 各クラスのインスタンスをBeanに登録するためのアノテーション // @Beanアノテーションを使ってBeanを登録できる @Configuration // (1). @EnableBatchProcessingをつけることでSpringバッチの設定が可能となる // Job生成用のクラス(JobBuilderFactory), StepBuilderFactory(Step生成用クラス) // などのクラスのインスタンスをDIできるようになる @EnableBatchProcessing public class BatchConfig { // (1.1). JobBuilderのFactoryクラス @Autowired private JobBuilderFactory jobBuilderFactory; // (1.2). StepBuilderのFactoryクラス @Autowired private StepBuilderFactory stepBuilderFactory; // (3). Stepから呼び出すTaskletをフィールドに設定する @Autowired private Tasklet helloTasklet; // (4). Jobから呼び出すStepを定義する @Bean public Step taskletStep1() { // StepBuilderFactoryを使ってStepを作成 return stepBuilderFactory.get("HelloTaskletStep1") // Builderの取得 .tasklet(helloTasklet) // Stepで実行するTaskletをセット .build(); // Stepを作成する } // (5). バッチとして実行するJobを定義する // @Beanをつけることで@ConfigurationをつけたこのクラスにBeanとしてJobを登録する @Bean public Job taskletJob() throws Exception { // (5.1). JobBuilderFactoryを使ってJobを作成する return jobBuilderFactory.get("HelloWorldTaskletJob") // Jobの名前を設定する .incrementer(new RunIdIncrementer()) // JobのIDをインクリメントさせるクラスを指定 .start(taskletStep1()) // 最初に実行するStepを指定する .build(); // Jobを作成する } }
まずは(1)のようにクラスに@EnableBatchProcessingというアノテーションを付けることで、Springバッチの設定ができるようにしましょう。 具体的にはこのアノテーションを付けることでJob生成クラス(1.1)やStep生成クラス(1.2.)などのバッチ処理の設定に欠かせないクラスのインスタンスをDIできるようになります。
次に(2)のように@Configurationというアノテーションを付けて、各クラスのインスタンスをBeanに登録できるようにしましょう。このアノテーションをクラスにつけることで、クラス内の@Beanを付けたものがBeanとして登録されます。
次に(3)のように先程作成したTaskletをフィールドとして設定しましょう。また@Autowiredをつけることで自動的にインスタンス化されるようにしておきます。
次に(4)のようにJobから呼び出されるStepを定義して、Stepで実行するTaskletをセットしてStepを作成するように実装します。
そして最後に(5)でバッチとして実行するJobを定義して、Jobの名前や最初に実行するStepを指定して最後にビルドメソッドを呼び出してJobを作成しましょう。
これでバッチ処理の実装は終了です。
5. 作成したバッチ処理を実行する
作成したバッチ処理を実行してみましょう。
Inttelli J IDEAではBatchHelloWorldTaskletApplication.javaを開いて、右上の矢印マークから実行を押しましょう。

上手く実行されれば、写真4のようにHello Worldが表示されます。
6. 最後に
今回はバッチ処理の基本機能を理解するためにTaskletモデルでHello Worldをコンソールに表示する簡単なプログラムを作成しました。
次回は一歩進んで、CSVを読み込んで加工して結果を別のCSVに書き込むバッチ処理をChunkモデルを使って実装していきたいと思います。